
Making Social Media Algorithms Social
Maximizing engagement isn't the same as maximizing community

I recently spent some quality time with the new X/Twitter algorithm source code. This is a complete rewrite of the previous version, and it got me thinking about how two apparently similar feed algorithms might have very different user experiences — both the “feel” of the product and the way it shapes the relationships between users.
Broadly speaking, platforms exist on a scale from Netflix to Discord. That is, completely entertainment-based to completely connection-based.

Two platforms might have all the same features — user generated content, liking and following, an algorithmic feed — yet work very differently in social terms. The key difference is something like: whether or not the platform succeeds in building new relationships between people.
Many, many people have found friendship and community on X/Twitter (shout out to TPOT). But in the last few years there’s been a vibe shift. The place has felt less friendly, less community-oriented. It’s hard to know if this is just me and my network, or if it’s a more general effect, but if it’s true, what might be causing it? Even better, how would we design a social media algorithm that is truly social?
What I’ve learned from reading the X source code, and from comparing it to the previous architecture, is how two algorithms could feel very different, even if they are optimizing for almost the same thing.
Fewer friends in For You
I’ve been trying to understand my different, less friendly experience of X/Twitter over the last few years. I’ve been on the platform since 2008 and have built up a large network of people I follow, so the first thing I wondered is how often posts from these people appear in my algorithmic feed.
This is the sort of thing I used to write code for, but instead I found a simple prompt for Claude Cowork that used my browser to figure out the percentage of posts in my For You feed that come from people I follow. This turned out to be 16%. I convinced two other people to try it, and they got 5% and 11%. (Try it yourself and leave a comment below!)
So, something like 10% of your For You feed is from people you follow. But it wasn’t always thus. Twitter told us in 2023,
We find candidates from people you follow (In-Network) and from people you don’t follow (Out-of-Network). Today, the For You timeline consists of 50% In-Network Tweets and 50% Out-of-Network Tweets on average, though this may vary from user to user.
Whatever else has changed, the fraction of posts in the For You feed from people you follow seems to have declined precipitously. This may be an intentional parameter change, or it may be the result of optimizing the fraction of in-network content so as to maximize engagement. Either way, you won’t see much from who you follow on the For You tab.
This follows a general trend which I call the TikTok-ification of social media. Starting around 2022 or so, many platforms started injecting more “out-of-network” or “unconnected” posts in their feeds. Facebook, Instagram, and LinkedIn all did this, clearly X has done it, probably others too. And that’s… fine I guess, but it’s not really going in the direction of “social” media because it doesn’t build social connections (as opposed to one-way parasocial interactions with creators). “Personalized television” would be a better description.
Retrieving posts by social similarity
I’m not against out-of-network posts, not at all. I think recommendations from all over the social graph can be a great way to discover new content and, ideally, make new friends. But it’s challenging to choose a few good posts out of the few billion per day that are posted to X/Twitter. The first, biggest filtering stage is called candidate generation (we explained the stages of a recommender in our last post).
Here’s how Old Twitter did candidate generation (as of March 2023, presumably for much longer before that):
How can we tell if a certain Tweet will be relevant to you if you don’t follow the author? Twitter takes two approaches to addressing this.
Our first approach is to estimate what you would find relevant by analyzing the engagements of people you follow
In other words, this method generates candidate posts by looking at what the people you follow liked (or retweeted, replied to, etc.) This is a classic, simple algorithm, and a version of this called LinkLonk powers the popular For You feed on BlueSky (just one of the many 3rd party feeds users can choose from over there).
The other big way Twitter used the social graph was by clustering all of its users into 145,000 or so overlapping communities with the SimClusters algorithm, which was published in 2020.
This gives every user a vector describing which communities they belong to, derived from the structure of the social graph. When a user engages with a post, their community vector gets added into that tweet's embedding vector, creating a time-decayed average. Thus the post’s embedding gradually comes to represent “the kind of user who likes this post” in community space.
Each user also has an “interested in” vector, representing the communities that the people they follow are most “known for.” A post is a good candidate for the user if the user’s interest vector is close to the post’s engagement vector in community space. In other words, if people from the communities of people they follow like it.
For all the gory details, see the SimClusters readme and this analysis.
Grok’s new way
As I dug through the code for the new Grok-based recommender (Claude was very helpful here) I discovered that it doesn’t use the social graph when picking out-of-network content. It again uses a shared embedding space for posts and users, but the embedding for a post is defined directly by which users engage with it — not which communities.
The transformer-based architecture predicts probability of user engagement directly (for 15 different actions) and posts are retrieved based on their probability of engagement. Again, see the readme and this analysis. The candidate posts are then ranked by multiplying these engagement probabilities by action-specific weights, and taking the sum.
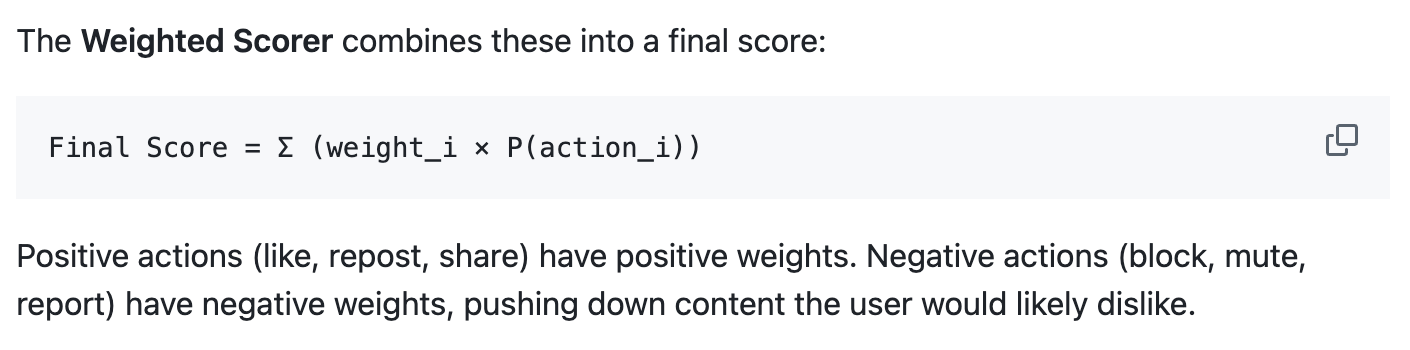
Old Twitter also ranked posts by predicting engagement and then taking a weighted sum. They even published the weights (sadly, the Grok algorithm repo now contains only dummy values). This approach to ranking is totally standard stuff. GreenEarth does it (you can customize the weights of course) and every production recommender I’ve ever seen does it too.
The difference between Old Twitter and Grok Twitter, then, is not the core ranking algorithm. They both try to maximize engagement! Instead, I wonder if Grok’s new candidate generation just doesn’t end up pulling in as many posts from the communities you care about. With billions of posts per day, it’s possible that the old and new algorithms end up selecting for really different parts of the content universe, even if they both produce about the same total engagement. Or maybe the new algorithm increases engagement, but that has come at the cost of moving the product somewhat away from “connecting” and toward “entertaining.”
Communities are made of triangles
All of this matters because meeting friends-of-friends is how communities are built in the real world. This is called triadic closure, and there’s empirical evidence for it: if A is friends with B and C, then B and C are likely to become friends too.
In the world of social networks, this means following someone that someone you follow follows. But you probably won’t do that unless you first see a post from them. Probably several posts; repeated exposure is how relationships form. And both reposts from friends (in-network posts) and posts from people that your existing community likes (ala LinkLonk and SimClusters) provide ample opportunity to repeatedly encounter your potential new internet BFF.
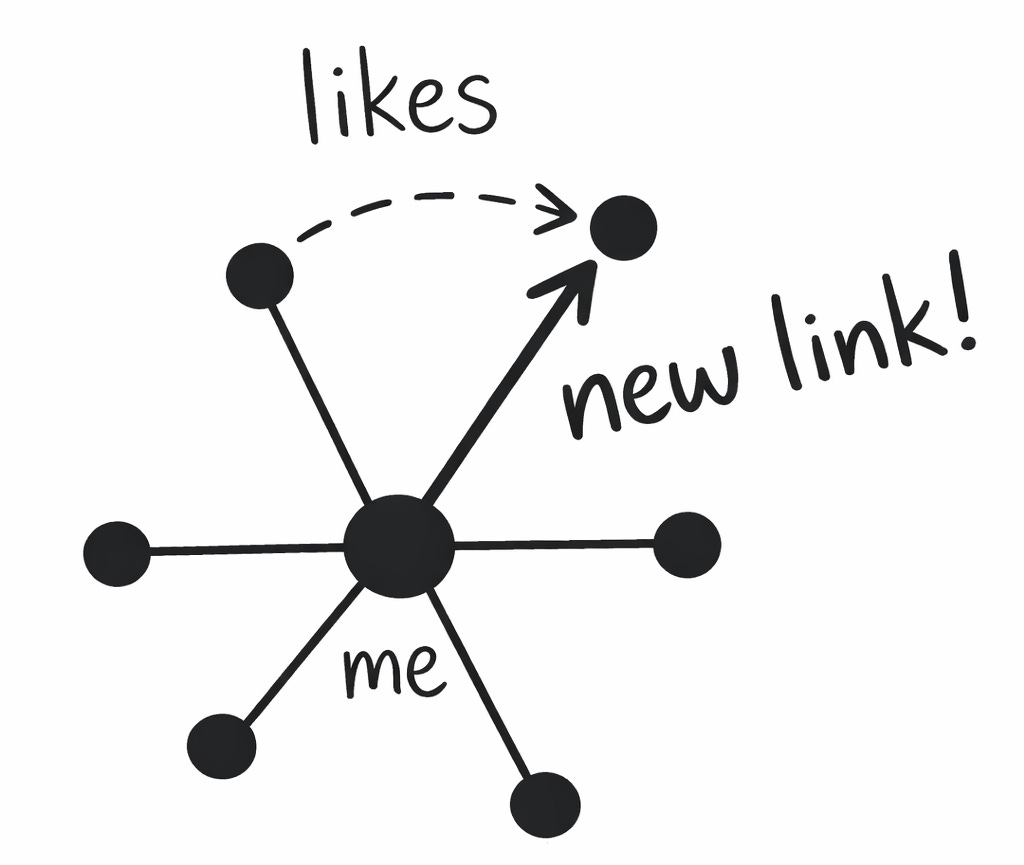
It’s easy to count triadic closure — just look for when someone follows a friend of a friend. I suspect that tuning the feed to increase this metric would create a community-building social media algorithm. Such triangles are key to how the Facebook “people you may know” recommender works (per Meta, and this study).
Here at GreenEarth, we’re certainly going to try it. Measuring the X feed composition and spelunking through the old and new Twitter code has given us valuable ideas about how community dynamics might play out algorithmically, and it’s influencing our candidate generator design. We’re not sure that we’re right about all of this, but we do know that we’re committed to building social media that is actually social. Stay tuned.