
Introducing GreenEarth
We're building advanced open source algorithms for social media

What if anyone could create a new algorithm for social media?
Many people have complained about social media feeds, including me. ATProto, the open protocol behind BlueSky, allows anyone to build a feed algorithm, and there are now thousands of feeds available in the BlueSky feed store. However, none of them rival the sophisticated personalized recommenders available on major platforms.
GreenEarth is a project to change that. Our goal is to make state-of-the art personalized feed technology available to everyone. Key features on our roadmap include interactive customization through LLM prompts (“show only the funniest cat videos”), engagement prediction models, and selectable candidate generators.
If you want classic reverse chron you are welcome to keep it, but modern recommender algorithms have many advantages. There is ample evidence that they greatly improve the user experience for a lot of people and thereby significantly boost retention, so you may want your ATProto app to include them. But we can do way better than the status quo of fixed, opaque, non-customizable feeds. The point is choice and control!
This post explains our goals, architecture, and how to get involved.
Goals
The GreenEarth project was founded with three goals:
Create a production “prosocial” feed. In particular, we want to productize the Prosocial Ranking Challenge, a large experiment where we showed that the right algorithms can make people hate each other less.
Create open recommender infrastructure. We aim to support not just our prosocial feed but a wide variety of feed types. “Open” means both open source and full support for algorithmic transparency, control, and research.
Support ATProto startups. In particular we are proud to partner with Graze.social (“create personalized feeds on ATProto, no code required”) and SkyLight (“the unbannable short form video platform”).
What we’re building
This is an infrastructure project which doesn’t have a unified user experience. Instead, our mission is to support a variety of projects which want to use algorithmic social recommenders in different ways. To do this, we are building a configurable recommendation architecture that looks like this:
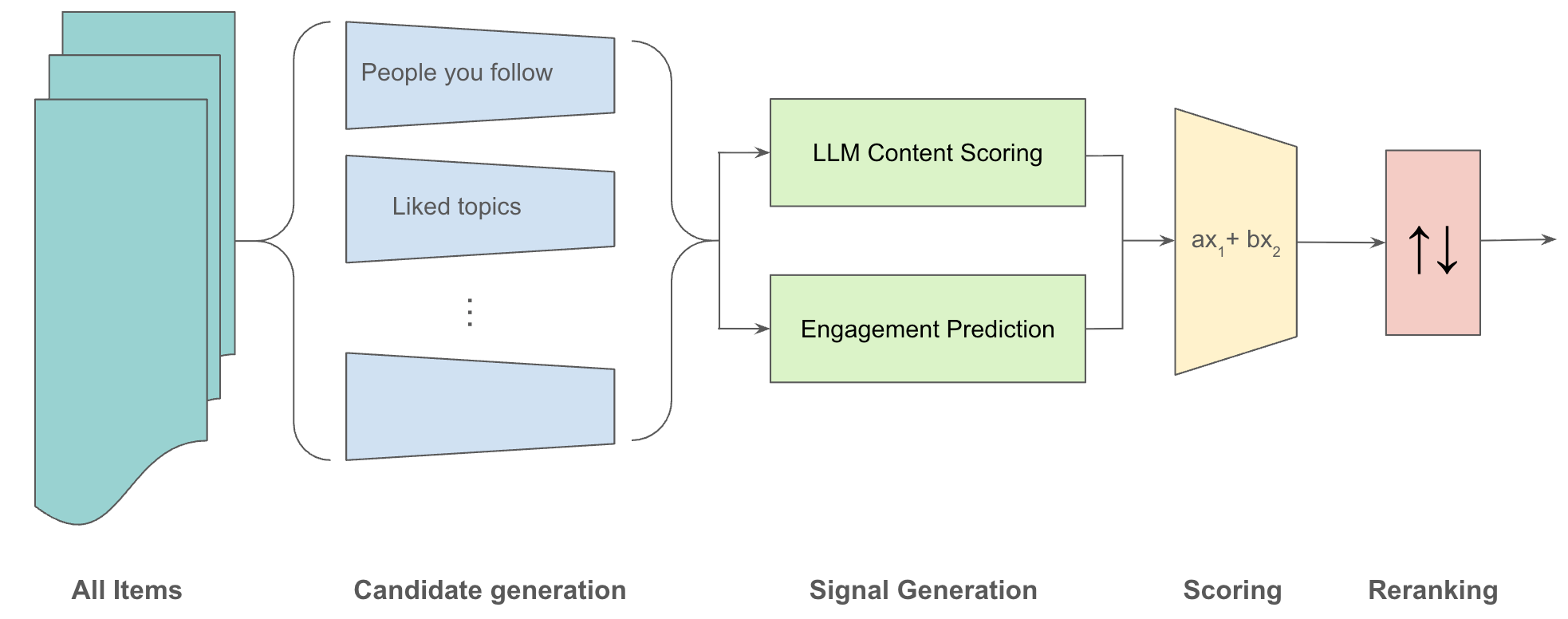
This is a fairly standard recommendation pipeline, broadly similar to what you will find in use at any major platform.
Starting with all possible items of content (billions) we first run a user-configurable set of “candidate generators” which each use a different approach to produce a much smaller set of items (hundreds) that might score highly in the final recommendation. There are many ways to do this, from just collecting every post from the people you follow, to searching the entire inventory for topics that you’ve previously liked, or analyzing your social network (Twitter’s source code includes several). The key point is that candidate generators have to run in sub-linear time on the available inventory, because their job is to select just a few posts out of an arbitrarily large set. So, this step is typically based on search engine technology, vector databases, etc.
These candidates will be merged and sent to a number of “signal generators,” each of which scores each post on one or more attributes. Our initial plan is to build two signal generators: an LLM scorer and an engagement predictor.
The LLM scorer will take a post and a prompt to produce a single “relevance” score. Users (or feed designers) will provide a prompt describing how to score post content, e.g. on a 10 point scale. You will be able to run multiple prompts against the same content to generate and combine different signals. We have prototyped a fast approximation algorithm that will allow interactive editing of prompts — change the wording and you’ll see your feed change. We think this is a killer feature (and btw we started building it before Elon announced something similar for X).
The engagement model will output the probability that a particular user will like, reply, follow, block etc. when they see a particular post. But isn’t optimizing for engagement the cause of all our algorithmic ills? Well, yes and no (see: What’s Right and What’s Wrong with Optimizing for Engagement). Engagement signals can sometimes select low-quality content, but they’re also essential for personalization. If you want to build any sort of recommender that gives people more of what they “like” (rather than just what’s popular overall) then engagement prediction is essential. So, we’re going to support it using a standard two tower model.
The result will be a vector of “signals” about each candidate post. The next step, scoring, will turn that vector into a single number indicating the rank of each post. The simplest way to do this is to assign linear “weights” to each signal indicating its importance, which is a surprisingly common approach. After scoring, posts are simply sorted by their final score to generate an initial ranking.
Signal generation and scoring are designed to be be highly parallel, so that they can run independently on each post. This can result in a lack of diversity, for example many posts in a row might be on the same topic or by the same author. The final step, re-ranking, takes the feed and potentially reorders, inserts, or deletes posts to ensure a good mix.
All of these steps will be user configurable. That is, you will be able to specify:
which candidate generators to use (e.g. just post from friends, or everyone)
the prompt(s) for LLM scoring
how all the LLM and engagement signals are combined into a final post score
which reranking or diversification algorithm to run
This may not be the simplest thing to get your head around if you’ve never seen it before. It might seem a little different than specifying keywords or user lists (though you can do that too, as a custom query for our search-based candidate generator). But we chose this because it’s a generalization of a tried-and-true production architecture that scales well. The set of candidate generators, prompts, scoring weights, and reranking rules is a design space that we are hoping many people will be able to create wonderful things with.
Using GreenEarth
There are several different types of “users” for our infrastructure. Here’s what we call them:
Consumers are the people scrolling generated feeds through BlueSky or another ATProto app like SkyLight. Some feeds may offer a UI for consumer customization, e.g. by editing prompts or adjusting scoring weights.
Feed builders are people who get deep into creating custom feeds. They might write code to call the GreenEarth API, or use graphical feed building tools like Graze.social.
Customers are the people who call the GreenEarth API directly.
But before any of this can happen we need to continuously ingest, analyze, and index every post in the ATProto universe in real time. That’s a big task all by itself, and thus the entire recommendation pipeline is a fairly hefty service. This is, of course, why no one has built it before. We will be offering GreenEarth both as open source code and, in association with our partners, a paid API with access to live data.
Timeline, team, and funding
We are aiming to have an MVP recommender system up in Q2 2026.
GreenEarth was founded by Renee DiResta (Georgetown University), Glen Weyl (Microsoft Research), and Jonathan Stray (UC Berkeley). Our core team includes Ian Baker as Director of Engineering (Berkeley) and Nikhil Garg as Director of Research (Cornell Tech) — plus a growing team of contributors.
We are currently funded by a seed grant of $300,000 from Project Liberty. Thank you!
How to get involved
We are building open social media algorithm infrastructure for everyone. We want a world where people have control over their feeds, and those feeds are both open source and open data (with appropriate privacy controls) so we can all understand how these algorithms work and what they are doing to us.
This is a big vision! We don’t have anywhere near the resources we need to accomplish it. You can help! We are currently focussed on building out our open source development team. Eventually, we will be inviting academic researchers to collaborate with us on open social media science!
If you’d like to be a part of GreenEarth, the easiest way is to join our discord and start asking questions! See also our Github repo.